Table of Contents
ToggleWhat is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG)
Purpose: This tutorial summarizes the core concepts, benefits, and challenges of Retrieval-Augmented Generation (RAG).
1. Introduction to Large Language Models (LLMs) and Their Challenges
Large Language Models (LLMs) are powerful tools that "generate text in response to a user query, referred to as a prompt." While LLMs "get some things amazingly right," they also exhibit "other things very interestingly wrong." Marina Danilevsky, a Senior Research Scientist at IBM Research, highlights two primary challenges associated with LLMs:
- Lack of Sourcing/Evidence: LLMs often provide confident answers "off the top of their head" without citing the source of their information. This is likened to a human confidently stating an answer without "source to support what I'm saying."
- Out-of-Date Information: LLMs' knowledge is limited to the data they were trained on. Consequently, their responses can be "out of date" if new information has emerged since their training. Danilevsky illustrates this with the example of the planet with the most moons: an LLM trained on older data might confidently state "Jupiter" while the correct, updated answer is "Saturn with 146 moons."
These challenges can lead to undesirable behaviors such as "hallucinat[ing] or mak[ing] up an answer" and potentially "leaking personal information" by relying solely on ingrained training data.
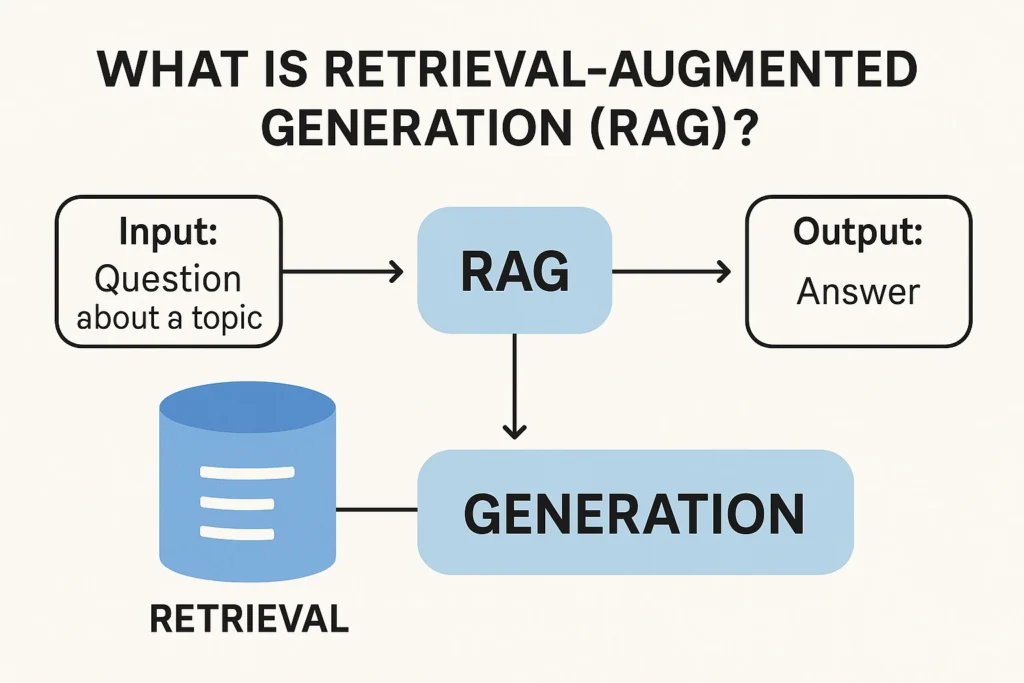
2. What is Retrieval-Augmented Generation (RAG)?
RAG is a framework designed to enhance the accuracy and currency of LLM responses by addressing the aforementioned challenges. It augments the "Generation" part of LLMs with a "Retrieval" component.
2.1. The Core Mechanism of RAG:
Instead of an LLM relying solely on its internal "parameters during its training," RAG introduces a "content store." This content store can be "open like the internet" or "closed like some collection of documents, collection of policies, whatever."
The RAG process unfolds as follows:
- User Prompt: The user asks a question to the LLM.
- Retrieval Instruction: In the RAG framework, the generative model receives an explicit instruction: "No, no, no. First, go and retrieve relevant content."
- Content Retrieval: The LLM "first goes and talks to the content store and says, 'Hey, can you retrieve for me information that is relevant to what the user's query was?'"
- Augmented Prompt: The original user's question is combined with the "retrieved content" and an instruction to "pay attention to" this content. This forms a new, three-part prompt for the generative model.
- Enhanced Generation: The LLM then "generate[s] the answer," utilizing the retrieved, up-to-date, and relevant information. This allows the model to "give evidence for why your response was what it was."
2.2. Benefits of RAG:
RAG directly addresses the two primary LLM challenges:
- Addressing Out-of-Date Information: RAG eliminates the need to "retrain your model" every time new information emerges. Instead, "All you have to do is you augment your data store with new information, update information." This ensures the LLM retrieves "the most up to date information" for a given query.
- Addressing Lack of Sourcing/Hallucination: By instructing the LLM to "pay attention to primary source data before giving its response," RAG significantly reduces the likelihood of hallucination. The model is "less likely to rely only on information that it learned during training," making its answers more grounded and verifiable.
Furthermore, RAG promotes a crucial positive behavior: "knowing when to say, 'I don't know.'" If the content store cannot "reliably answer" the user's question, the RAG-enabled model "should say, 'I don't know,' instead of making up something that is believable and may mislead the user."
3. Current Challenges and Future Directions in RAG
While RAG offers significant improvements, challenges remain:
- Retriever Quality: A potential "negative effect" arises "if the retriever is not sufficiently good to give the large language model the best, most high-quality grounding information." This could lead to a situation where an "answerable" query does not receive an answer because the relevant information wasn't retrieved.
Researchers, including those at IBM, are actively working on improving RAG from both ends:
- Improving the Retriever: Efforts are focused on enhancing the retriever's ability "to give the large language model the best quality data on which to ground its response."
- Improving the Generative Part: Work is also being done to ensure "the LLM can give the richest, best response finally to the user when it generates the answer."
In conclusion, RAG is a critical framework for making LLMs more reliable, accurate, and trustworthy by integrating external, up-to-date data sources into their generation process.
Retrieval-Augmented Generation (RAG) - FAQ
What is the core problem that Retrieval-Augmented Generation (RAG) aims to solve with Large Language Models (LLMs)?
RAG addresses two primary challenges with traditional LLMs: providing outdated information and generating unsourced or "hallucinated" content. LLMs, when solely relying on their training data, can confidently present information that is no longer current or invent plausible but incorrect answers without any verifiable source. RAG introduces a mechanism to ground the LLM's responses in up-to-date, external knowledge.
How does the "Generation" part of RAG function in a standard LLM before augmentation?
Before augmentation, the "Generation" part of an LLM involves it creating text in response to a user's prompt by drawing solely on the information it learned during its training phase. The LLM acts as if it "knows" the answer based on its internal parameters, even if that knowledge is outdated or incomplete, and will confidently generate a response without providing external sources.
What undesirable behaviors can be observed in LLMs without Retrieval Augmentation?
Without Retrieval Augmentation, LLMs often exhibit two undesirable behaviors:
- Out-of-date information: Their knowledge is limited to their last training update, meaning they can provide answers that are no longer accurate due to new discoveries or changes.
- Lack of sourcing/Hallucination: They generate responses without referencing external sources, making it difficult to verify the information. This can lead to "hallucinations," where the model invents plausible but factually incorrect details.
How does the "Retrieval-Augmented" component transform the LLM's response process?
The "Retrieval-Augmented" component transforms the LLM's response process by introducing a content store (which can be open like the internet or closed like a private database). Instead of relying solely on its internal training, the LLM first consults this content store to retrieve information relevant to the user's query. This retrieved content is then combined with the original query, guiding the LLM to generate a more accurate, up-to-date, and grounded answer.
What are the three key components of a prompt within the RAG framework?
Within the RAG framework, a prompt sent to the LLM has three key components:
- Instruction to pay attention to: A directive for the LLM to consider the retrieved content.
- Retrieved content: The relevant information pulled from the external content store.
- User's question: The original query posed by the user. These three parts together allow the LLM to generate a more informed and evidence-based response.
How does RAG specifically address the "out-of-date" information problem?
RAG addresses the "out-of-date" information problem by allowing updates to the content store independently of the LLM's training. Instead of requiring costly and time-consuming retraining of the entire model when new information emerges (like new planetary moons), one only needs to update the data in the content store. The LLM will then retrieve the most current information the next time a relevant query is made, ensuring its answers are up to date.
How does RAG mitigate the issue of LLM "hallucinations" and improve sourcing?
RAG mitigates hallucinations and improves sourcing by instructing the LLM to base its response on primary source data retrieved from the content store. This significantly reduces the likelihood of the model inventing answers or relying solely on potentially inaccurate information learned during training. By grounding its responses in retrieved evidence, the LLM can also explicitly provide sources, making its answers more trustworthy and verifiable.
What is a potential negative side effect of RAG, and how are researchers working to address it?
A potential negative side effect of RAG is that if the retriever component is not sufficiently effective at finding high-quality, relevant information, the LLM might incorrectly respond with "I don't know" even if the answer is theoretically available within the data store. This means a perfectly answerable query could go unanswered. Researchers, including those at IBM, are actively working to improve both sides of the RAG system: enhancing the retriever to fetch the best possible grounding data and improving the generative part of the LLM to formulate the richest and most accurate responses based on that data.
Posts Gallery

Agentic AI for Enterprise Automation
Discover how Agentic AI revolutionizes enterprise automation, boosting efficiency and strategic decision-making.
Read More →
How Agentic AI Works: Intent to Execution
Unpack the intricate process of Agentic AI, from understanding user intent to executing complex tasks autonomously.
Read More →
Purpose & Use Cases of Agentic AI
Explore the diverse applications and strategic importance of Agentic AI across various industries and daily operations.
Read More →
What is Agentic AI?
A foundational article explaining the core concepts of Agentic AI, defining its components and its role in modern automation.
Read More →
Why Agentic AI?
Understand the compelling reasons and significant benefits that make Agentic AI a transformative technology for efficiency and innovation.
Read More →
AI Tools Spotlight
A comprehensive overview of cutting-edge AI tools that are shaping the future of automation and intelligent systems.
Read More →
