Table of Contents
ToggleHow to Chose LLM's : Developer's Guide

Audio Podcast on ‘How to Choose LLM’
Developer's Guide to Choosing Large Language Models (LLMs)
This tutorial offers practical tips for choosing and using LLMs, emphasizing real-world use cases over benchmarks, with tools for evaluation and local deployment.
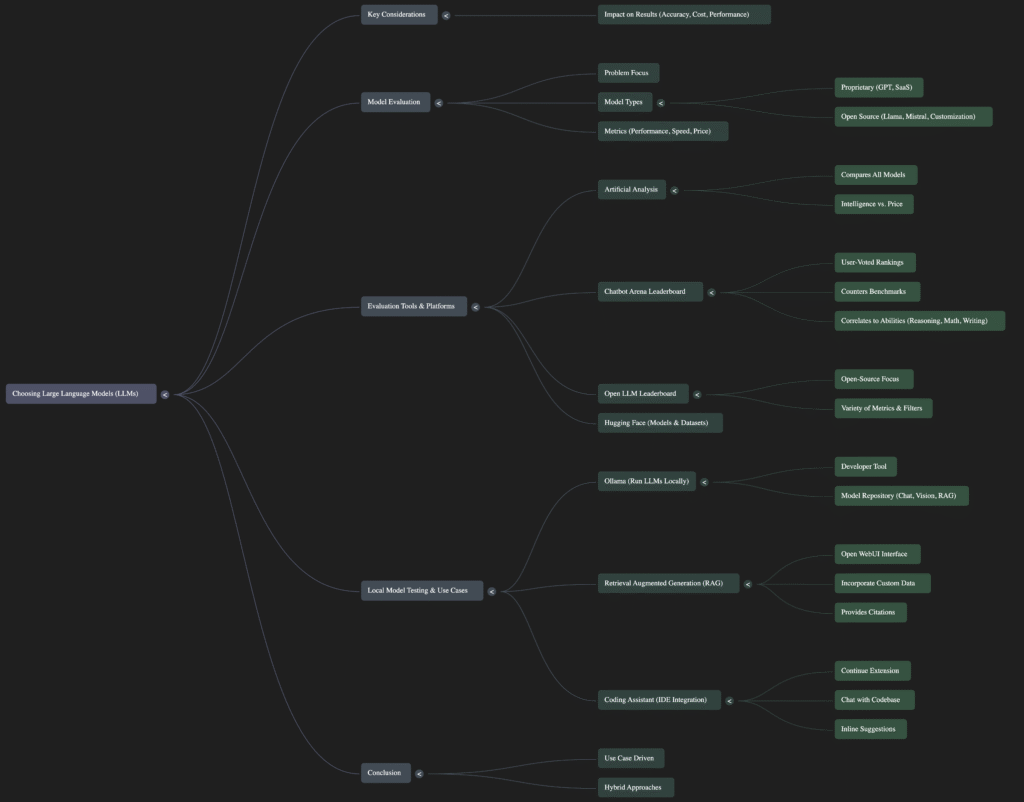
I. Core Considerations for LLM Selection
The fundamental principle for choosing an LLM is "the problem that you're trying to solve." This dictates the trade-offs between various model characteristics.
A. Proprietary vs. Open-Source Models
- Proprietary Models (SaaS-based, e.g., GPT):
- Pros: "an easy and fast way to begin prototyping."
- Cons: Less control, customization, and flexibility.
- Open-Source Models (e.g., Llama, Mistral, Granite):
- Pros: Offer "full control, customization, and flexibility."
- Cons: May require more setup and management.
B. Key Performance Metrics
Regardless of the model type, developers must consider:
- Performance: Accuracy and quality of results for the specific task.
- Speed: Inference time and responsiveness.
- Price/Cost: Especially relevant when "scaling things up to millions of queries." There's a general trend that "with higher intelligence, typically results in a higher price or higher cost. While at the same time, smaller models might result in faster speeds and lower costs at the same time."
C. Intelligence vs. Task Complexity
Not every task requires a highly intelligent, expensive model. For "a simple task," a "PhD-level AI" may be unnecessary. The level of intelligence needed should align with the task's complexity.
II. Evaluating and Benchmarking LLMs
The guide highlights several tools and platforms for evaluating LLMs, moving beyond traditional benchmarks.
A. Online Leaderboards and Comparison Tools
- Artificial Analysis: Offers a broad comparison across "the entire landscape of models, both proprietary and open source," noting trends between intelligence, price, and speed. Intelligence scores are derived from "a variety of benchmarks on MMLU-Pro and similar evaluations."
- Chatbot Arena Leaderboard (UC Berkeley and ALM Arena):
- Methodology: Combines "over a million blind user votes on models to rank them and essentially provide a vibe score."
- Value: "a great way to understand what the general AI community thinks is the best model" because "benchmarks sometimes can be reverse engineered by models."
- Functionality: Allows direct comparison between two models with a given prompt (e.g., "Granite 8 billion and Llama 8 billion" for a customer response in JSON).
- Correlates to: "its abilities on reasoning, math, writing, and more."
- Open LLM Leaderboard:
- Focus: "simply open-source foundation and fine tune models."
- Features: Provides "a wide variety of model metrics and filters" for specific use cases, such as models runnable "if you have a GPU or you wanna run it locally on your machine or even do real-time inferencing on a mobile or edge device." Links directly to Hugging Face for model details.
B. Hugging Face
A crucial resource for "understanding the millions of models and datasets that are on there and understand how you can use it on your machine."
III. Local Deployment and Testing with Your Data
The guide strongly advocates for local testing to validate model performance with specific datasets and use cases.
A. Ollama
- Purpose: "a popular developer tool that enables everybody to run their own large language models on their own system."
- Features: Open-source, includes a "model repository," meaning that "we can run chat, vision, tool calling, and even a rag-embedding models locally."
- Practicality: Simplifies running models like "Granite 3.1" locally, often already "quantized or optimized and compressed for our machine."
B. Open WebUI for RAG and AI Applications
- Purpose: "an open-source AI interface" for using local models (via Ollama) or remote OpenAI-compatible APIs.
- Analogy: Functions as the "front end" of an AI application, with the model and server as the "back end."
- Key Use Case: Retrieval Augmented Generation (RAG):
- Process: Enables models to leverage "specific enterprise data," which "the model wasn't trained on originally" by attaching a file.
- Mechanism: Uses "an embedding model in the background, as well as a vector database" to "pull certain information from that source document and even provide that in ah the citations here to have a clear source of truth for our model's answers."
- Benefits: Allows models to answer questions on proprietary data (e.g., "What happened to Marty McFly in the 1955 accident from the claim?") and provides verifiable sources.
C. Integrating LLMs into Development Environments (IDEs)
- Tool: Continue is an "open-source and free extension from the VS Code marketplace or IntelliJ" that can use local LLMs (e.g., Granite via Ollama).
- Functionality: Enables "chat with our code base, explain entire files, and make edits for us."
- Example: Demonstrates adding "java.comments describing the service" directly within the IDE, with the option to approve or deny the AI's suggestions.
IV. Conclusion: The Importance of Use Case and Experimentation
The guide concludes by reiterating that "it all comes down to your use case." It also notes the possibility of "hybrid approaches of using a more powerful model in conjunction with a small model on device," indicating the evolving nature of LLM deployment strategies. The emphasis is on experimentation and building practical AI applications after model evaluation.
Developer's Guide to Choosing Large Language Models (LLMs) - FAQ
1. How should developers approach selecting a Large Language Model (LLM) for their projects?
Developers should prioritize the specific problem they are trying to solve when selecting an LLM, rather than immediately looking at benchmarks. While SaaS-based models like GPT offer quick prototyping, open-source models like Llama or Mistral provide greater control, customization, and flexibility, which are often crucial for organizations. Key considerations for any choice include performance, speed, and price.
2. What are some key factors to consider when evaluating LLMs, and how do they typically relate to each other?
When evaluating LLMs, developers should consider intelligence, price, and speed. Generally, higher intelligence in an LLM tends to correlate with a higher price. Conversely, smaller models often result in faster speeds and lower costs. The level of "intelligence" needed should be matched to the task; a "PhD-level AI" isn't necessary for simple, high-volume queries.
3. What are some reliable platforms and tools for evaluating LLMs, both proprietary and open-source?
Several platforms can assist in evaluating LLMs:
- Artificial Analysis: This platform allows for comparing a wide range of proprietary and open-source models, highlighting trends such as the relationship between intelligence and cost. It uses benchmarks like MMLU-Pro for intelligence scores.
- Chatbot Arena Leaderboard (UC Berkeley and ALM Arena): This community-based platform uses over a million blind user votes to rank models, providing a "vibe score" that reflects general community sentiment and real-world performance on reasoning, math, and writing, often more reliably than benchmarks alone. It also allows for direct model comparisons.
- Open LLM Leaderboard: Specifically for open-source foundation and fine-tuned models, this platform offers various metrics and filters, useful for developers considering running models locally on GPUs, mobile, or edge devices.
- Hugging Face: This platform hosts millions of models and datasets, providing details on how to use them locally.
- Ollama: An open-source developer tool that enables running LLMs (including chat, vision, tool calling, and RAG-embedding models) locally on one's own system.
- Open WebUI: An open-source AI interface that facilitates using local models (e.g., via Ollama) or remote OpenAI-compatible API models. It functions as a front-end for AI applications, allowing custom data integration and agentic applications.
- Continue: A free, open-source extension for IDEs (VS Code, IntelliJ) that allows users to leverage local LLMs (e.g., Granite via Ollama) for coding assistance, such as chatting with codebases, explaining files, and making edits with inline approval.
4. How can developers test LLMs locally with their own data?
Developers can test LLMs locally using tools like Ollama, which allows them to run models directly on their system. Once a model is running locally (e.g., a quantized Granite model), they can utilize an interface like Open WebUI. This interface enables them to integrate their own custom, enterprise-specific data (e.g., through RAG or Retrieval Augmented Generation) and ask questions that the model wouldn't have been originally trained on. RAG, combined with an embedding model and vector database, allows the model to pull relevant information from source documents and even provide citations for verifiable answers.
5. What is Retrieval Augmented Generation (RAG) and how does it enhance LLM capabilities?
Retrieval Augmented Generation (RAG) is a technique used to provide LLMs with specific, often proprietary or real-time, information that they were not originally trained on. It works by using an embedding model and a vector database to retrieve relevant information from a source document based on a query. This retrieved information is then provided to the LLM as context, allowing it to generate more accurate and informed responses, often with citations to the source data. This is particularly useful for enterprise data or scenarios where a "source of truth" is required for the model's answers.
6. Can LLMs assist with software development, and if so, how?
Yes, LLMs can significantly assist with software development. Tools like "Continue" (an open-source IDE extension) allow developers to use local LLMs as free coding assistants. These LLMs can:
- Chat with the codebase.
- Explain entire files.
- Suggest and make edits, such as adding comments and documentation to code (e.g., Java comments), which can then be approved or denied by the developer. This streamlines documentation and code understanding for other developers.
7. Why might the "Chatbot Arena Leaderboard" be a more reliable indicator of a model's true capabilities than traditional benchmarks?
While benchmarks can be useful, models sometimes "reverse engineer" them, leading to potentially inflated scores that don't fully reflect real-world performance. The Chatbot Arena Leaderboard, in contrast, relies on over a million blind user votes, providing a "vibe score" that captures the general AI community's perception of a model's effectiveness. This community-driven evaluation directly correlates with a model's practical abilities in areas like reasoning, math, and writing, offering a more holistic and user-centric view of its true capabilities.
8. Is it possible to combine different LLM approaches for optimal results?
Yes, hybrid approaches are possible and often beneficial. Developers can combine a more powerful, potentially cloud-based, model with a smaller model running locally on a device. This allows for leveraging the strengths of both, such as using the powerful model for complex tasks and the smaller, on-device model for real-time inferencing or tasks requiring less "intelligence," balancing performance, cost, and speed according to the specific use case.
Posts Gallery

Agentic AI for Enterprise Automation
Discover how Agentic AI revolutionizes enterprise automation, boosting efficiency and strategic decision-making.
Read More →
How Agentic AI Works: Intent to Execution
Unpack the intricate process of Agentic AI, from understanding user intent to executing complex tasks autonomously.
Read More →
Purpose & Use Cases of Agentic AI
Explore the diverse applications and strategic importance of Agentic AI across various industries and daily operations.
Read More →
What is Agentic AI?
A foundational article explaining the core concepts of Agentic AI, defining its components and its role in modern automation.
Read More →
Why Agentic AI?
Understand the compelling reasons and significant benefits that make Agentic AI a transformative technology for efficiency and innovation.
Read More →
AI Tools Spotlight
A comprehensive overview of cutting-edge AI tools that are shaping the future of automation and intelligent systems.
Read More →
